
Generative AI 102: Launching POCs, mitigating risks
When you’re ready to go beyond the hype and dabbling – and find practical ideas to take back to your colleagues – it’s time for Generative AI 102.
In this second article in our generative AI series (see Gen AI 101 here), we harnessed the brain power of Allan Chong and Stephen Russell from our Advanced Data Solutions team, together with Max Mikkelsen, our Head of Transform. It also brings in insight from Microsoft’s Johan Lövh, Senior Microsoft Solution Specialist and Lukas Lundin, Azure Go-to-market Manager.
They’re all working on active gen AI projects and shared insight at Nordcloud’s recent event with Microsoft called OpenAI: Don’t just play, make it pay. The following topics are taken from the Q&A session and discussions at the event.
Let’s get started… 👇
POC types
What are common starting points for gen AI POCs?
Two common gen AI use cases are SafeGPT and a chatbot using semantic search.
SafeGPT involves enabling people to use ChatGPT with an added layer of control. Instead of using the public OpenAI.com version, you get ChatGPT in a controlled environment that offers greater data protection and security.
SafeGPT opens up so many efficiency boosts. People can upload their documents and get summaries, understand the sentiment of customer feedback, generate job descriptions and more.
Azure OpenAI Service makes this simple. For one customer, where employees wanted a way to use ChatGPT, we also leveraged Microsoft's cognitive search and governance features. The integration allowed us to put security and authentication structures in place, together with company branding on the user interface. With this approach, everyone can use ChatGPT while ensuring all information is kept in-house and not used to train other models. Stored chat history and conversation memory for the model mean people get more accurate and contextual responses.
Deployment, customisation and testing take less than a week, and you only need a small team – say 1 data scientist/developer, 1 cloud engineer and 1 project manager.
For the chatbot using semantic search, the aim was to enhance the employee experience of using the intranet by connecting ChatGPT to internal data sources like SharePoint.
Employees could ask questions related to company policies – like annual leave requests, expense queries or training documents – and ChatGPT would retrieve relevant answers from the internal documents. This approach eliminated the need for cryptic search terms and allowed users to interact with intranet in a more intuitive way.
This POC took less than 2 weeks, and also only needed a small team of 1 data scientist/developer, 1 cloud engineer and 1 project manager.
(Read more about these POCs here.)
A third use case involved IT management. We used gen AI to enrich monitoring data, making it easier to input resources involved in incidents. When an incident pops up, the system automatically comments on the ticket with a list of all processes and relevant stats, saving engineers loads of time and speeding up responses.
These are just 3 examples. Here’s a summary of low-hanging fruit gen AI use cases for POCs:
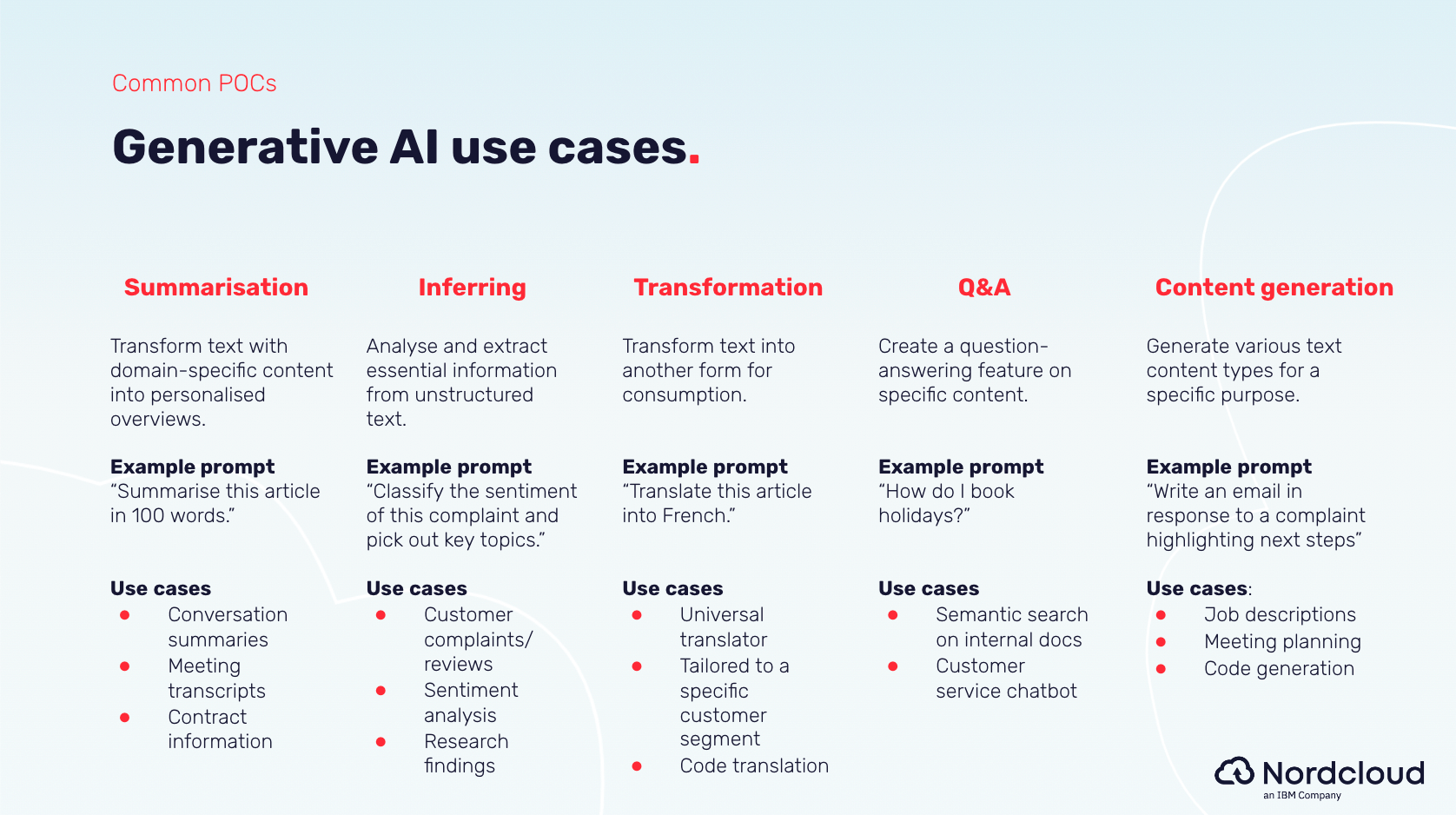
How do you cost gen AI programmes for customers?
There are a couple of approaches.
A basic one is sprint-based – where we map out the design and delivery roadmap and cost it based on the sprints required to deliver it.
But the better approach is business-focused – where we analyse the business case and ROI. As with any deployment, you can’t just have a ‘build it and they will come’ mindset. You need to engage stakeholders throughout to make sure people will use what you’ve deployed. You then follow a similar process to other application development projects, where you do a roadmap, engage stakeholders in bringing ideas, and then do the design and delivery.
From a business case perspective, it’s important to think about how the use case will both increase the top line and reduce costs. A chatbot, for instance, can increase loyalty and improve cross-selling, which generates revenue. But it can also prevent people from needing a human agent, which reduces operational costs.
What are your top lessons learned and ‘gotcha’ moments from production-deployed generative AI-powered solutions?
First, you need a mindset change for people to trust the solution
This is the same as other new tech deployments.
Take gen AI-powered customer service bots as an example. You can’t predict what the bot will say 100% of the time. Through development and testing you can get certainty up to 99 point something percent – such as by limiting the token amount, question length, type of question it handles. But there is still that tiny gap of uncertainty.
People need a change of mindset to accept that uncertainty. The funny thing is that they willingly accept an even greater variability with human agents, but because it’s new technology, you have that mental barrier to overcome.
Second, you need a certain level of generative AI knowledge across the organisation
That knowledge doesn’t need to be deep, but at a 101 level at least so people know it’s coming and can’t hide their heads in the sand. Having that baseline allows you to educate people on the basics of how to use gen AI. Again, this goes back to the human factor. Yes, it’s a technology, but there are always human elements in the loop – human users, developers and testers.
Like with the initial onset of public cloud, you need upskilling at the right level for people’s roles. (You can learn more about planning upskilling pathways here.)
Third, don’t forget the basics
This can be tempting, given that gen AI is a shiny new tool. But it’s still a technology that requires the usual networking, authentication, governance and compliance considerations. And make sure you have thorough testing to ensure it follows the organisation’s policies and tone of voice – and doesn’t step outside its intended usage.
Skills requirements
What data science skills do you need for gen AI projects?
The SafeGPT and semantic search use cases we described above only required a small team – 1 data scientist/developer, 1 cloud engineer and 1 project manager.
A common misconception is that you need lots of data scientists for gen AI. You don’t. The LLMs are already built – you don’t have to do any training on them. Technically, you only need a developer to send an API call to that model.
The data science skills come in when you want to fine-tune a model or build your own LLM. But because foundation models have so much power and billions of parameters, the out-of-the-box LLMs are very good enough for most use cases.
Do you need a different division of labour within teams to deliver and support gen AI projects?
It follows a similar model to agile, product-based organisations.
Let’s say you have Azure OpenAI endpoints available internally…
- IT infra is responsible for maintaining endpoints for the model. They follow the throughput of that model, and their only task is to ensure use cases have capacity so you don’t have service bottlenecks
- Software development teams work with the business units on different use cases
- Business units own the data
Here’s an example: HR wants to make a bot for employees to ask questions. The software development team works with HR to create the solution and is responsible for plugging into the API, working with business and maintaining the data. IT infra's only task is to keep the infrastructure up and running and secure (the basics).
Data quality and model training
How can companies start using gen AI for use cases like customer service and cross-selling when they don’t have much quality data?
Because it's gen AI, you can ask it to make you data 😀
Say you want to create personas for new customer types and don’t have any way of speaking to people in that role. Make the persona using gen AI. Then ask the gen AI-powered persona questions. It actually gives pretty good responses you can use as a baseline for planning your activities.
You can also use gen AI to improve data quality. Say you have a product database of information supplied by suppliers. It’s very technical and not very readable. Use gen AI to write product descriptions based on that data, which can be used internally for people to better understand the offering.
In both these examples, the best starting point is setting up a SafeGPT environment so people can start experimenting and understanding possible use cases – from customer service virtual assistants and sentiment and social media analyses to potential demand forecasting, fraud detection and internal process automation.
How do you train your model based on user responses/feedback, to improve quality?
There are different levels of training:
- At the most basic level, you can do this with few-shot prompting. This is where you provide examples in your prompt so the model has a framework for how it should respond
- Another level is retrieval-augmented generation (RAG), where you put company data into the model for training purposes. This is the type of training we do with use cases involving search portals
- The third level is the more compute-heavy fine-tuning, where you’re training the model based on data sets. Microsoft has developed a way for you to fine-tune quite easily through Azure OpenAI Studio, but it’s worth considering whether you actually need this approach
To enable a user feedback loop, you need a combination of retrieval-augmented generation and fine-tuning. You’re essentially feeding in a data set of user responses saying ‘This answer was good because of X’. And that slowly trains the model.
Risk mitigation
What security guardrails should be in place to protect against threat actors gaining access?
Again, cover all the security basics across networking and authentication. And there are gen AI-specific ways to mitigate threats, such as having a separate evaluator LLM or restricting prompt length. This will be an evolving area as gen AI matures, but our suggestion is to start with internal use cases to limit exposure. (There’s more detail on this in our Cloud Core podcast episode on gen AI.)
This is also why the SafeGPT approach is important. Azure OpenAI Service lets you host ChatGPT 3.5 and 4 on your own Azure environment. Thus, everything you do with Azure OpenAI (as opposed to the public OpenAI) is protected within Microsoft. None of your prompts, completions or embeddings are sent publicly or used to train other OpenAI models. This Microsoft article gives you more in-depth security information.
Given the global shortage of GPUs, will we end up with ‘have’ and ‘have nots’ in regards to AI service availability? What should organisations do to guarantee critical AI services?
We don’t have a crystal ball for the future, but at the moment, Azure OpenAI Service has a 99.9% SLA, and every endpoint has a certain token per minute limit provisioned with it. For enterprise-grade cases, there are provision throughput units (PTUs) – basically reserving Azure OpenAI capacity for the long run.
But as with any service, don’t forget the basics like disaster recovery and business continuity plans.
Congrats on completing your second gen AI ‘module’!
Want more tips on identifying priority use cases and deploying POCs quickly, cheaply and securely?
Get in touch with Risto using the form at the bottom of this page ⬇️









Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
