
Migrating a Splunk Enterprise Environment to AWS: What to consider
Splunk is a leading and widely used application in Enterprises for different purposes, such as monitoring of servers and applications for analytics, security and compliance.
At enterprise level, Splunk could be used as a main shared service to collect all information about your IT infrastructure in a single centralised repository. Giving you the ability to collect real-time collection, indexing and analysis gives enterprises several opportunities to act on their IT infrastructure in a quick and structured manner. Therefore, in a real enterprise environment, migration of such a service from on-premises to AWS without any downtime to the real-time flow of data is crucial.
This is where Nordcloud’s expertise comes into play.
There are a few resources on the internet on how to migrate from on-premises to AWS. And If you plan to create a new Splunk Enterprise environment on AWS, there is a deployment guide prepared by AWS and Splunk officially here.
However, these resources don’t touch on the real burden of the migration of the Splunk Enterprise from on-premises to the AWS in detail.
In this article, I’ll explain the critical points that you should consider before you move the Splunk Enterprise running on your on-premises to AWS.
During a data centre exit project - where the timeline is fixed and enforces a project requirement of “rehost wherever possible” - with your limited resources you might have some difficulties to refactor your Splunk Enterprise to use AWS cloud-native services.
If you’re planning to design your Splunk Enterprise from scratch and you’ll be operating in AWS, I’d recommend taking a look at the following diagram to see how to use AWS services for the setup.
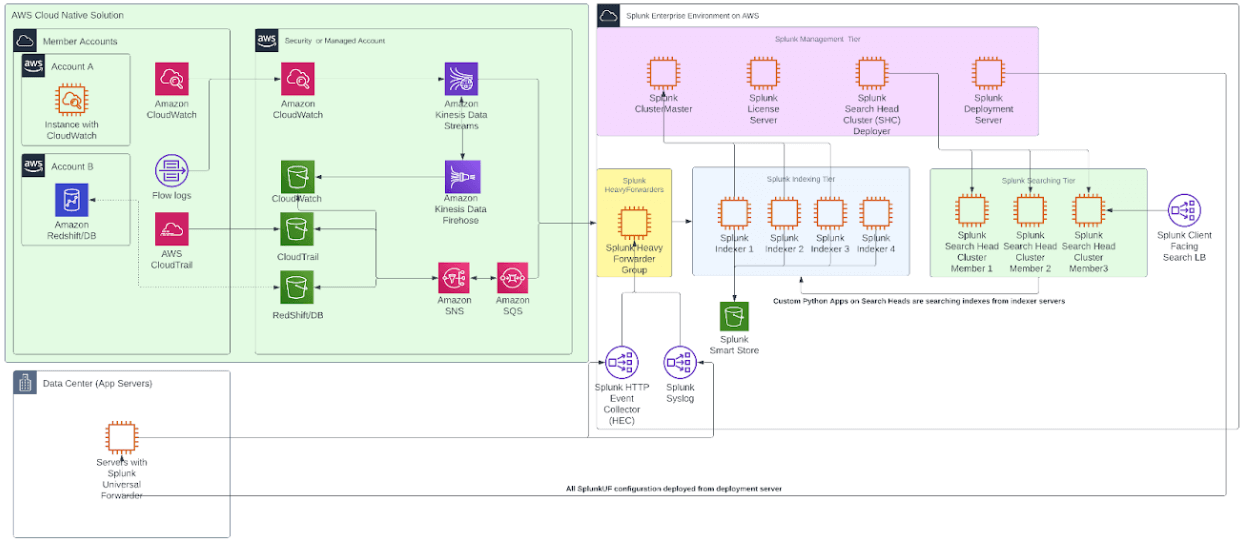
But in this post, we’ll assume that you’d like to move your existing setup to the AWS with minimum effort and keep the current state as is.
Before providing migration strategy in detail, we should start by listing the different components of the Splunk Enterprise environment to make you familiar with each part. There are different approaches for migrating each component to AWS without causing major downtime.
Splunk Enterprise Structure
In general, the Splunk Enterprise environment has 4 main tiers;
- Indexing tier
- Searching tier
- Forwarding tier
- Management tier
In summary, these 4 main tiers have following characteristics:
Indexing Tier
This is the core tier of the Splunk system where heavy indexing tasks are being done on the forwarded logs - by the heavy forwarders to Splunk. Compute and Disk Write heavy tasks are being done by this tier. Indexers are storing data on their own hard drives into 5 types of bucket structure: hot, warm, cold, frozen, and thawed.
Searching Tier
This tier consists of search head servers which have mostly Python apps, dashboards and reports. They’re mainly using the indexes stored by indexers.
Forwarding tier
Consists of Splunk forwarders, which is a pre-indexing server to help indexer servers for basic tasks on raw log data (Syslog or HTTP Event) from Splunk universal forwarders, such as providing timestamp, hostname, tags, etc.
Management tier
Consists of Cluster Master, License Server, Search Head Deployer and Deployment Server, which are mainly responsible for the management of the above tiers.
Steps of Splunk Enterprise Migration
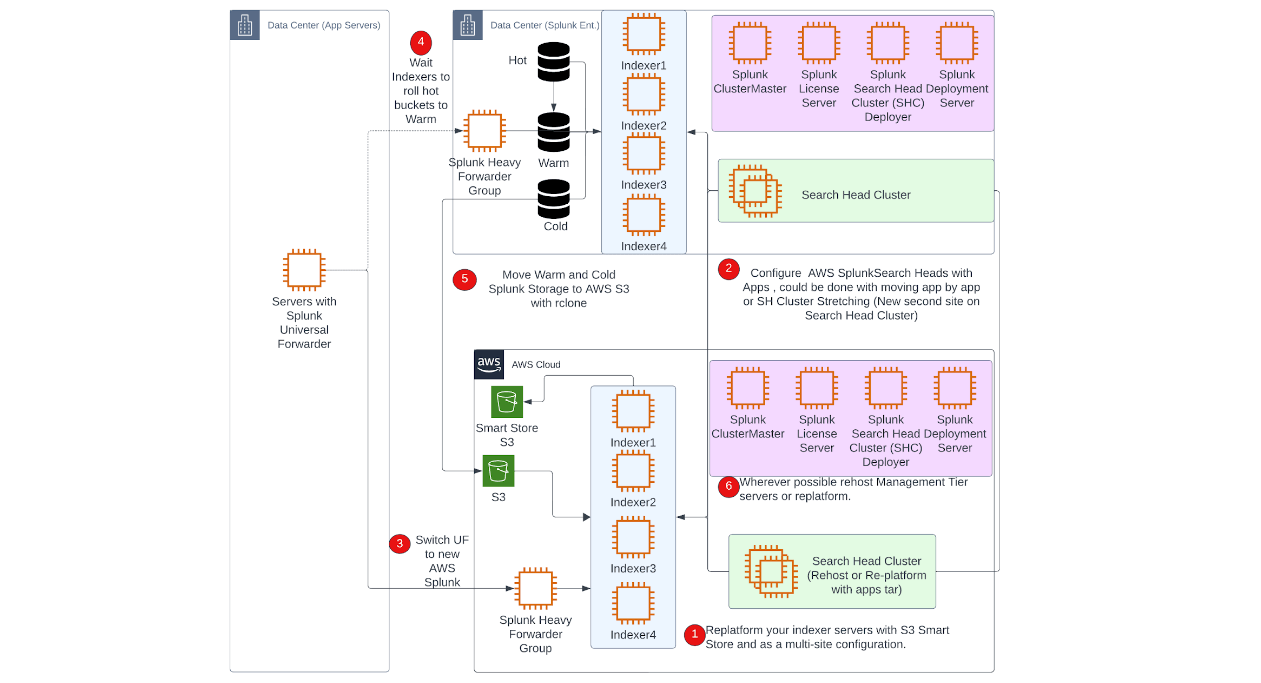
In the following diagram, you’ll see the steps of the migration to AWS. To avoid downtime, capabilities of both AWS and Splunk application specific configurations need to be used in combination for a successful migration from a technical perspective.
In addition to technical readiness for such a migration, choosing an appropriate partner to walk through your journey is crucial, alongside technical readiness. Your partner should provide:
A target architecture and migration plan which is adjusted according to your needs to give the end picture of your environment that is going to be operated in the cloud.
Continuous communication and close collaboration with you to provide solutions to overcome issues throughout the migration.
Expertise to offer different solutions to your needs.
As described in the diagram, you could plan your migration in 5-6 phases;
1. Re-platform your Splunk indexers on AWS with AWS S3 backed Splunk Smart Store solution for storage of indexes.
2. Re-platform or re-host your Splunk Search Head Clusters on AWS.
3. Test your new Splunk Environment and switch your Heavy Forwarders from on-premises to ingest data into your new AWS Splunk environment.
4. Wait for existing index jobs to be finalised by indexers.
5. Initiate existing data migration from on-premises to AWS.
6. Within the same phases , you could re-platform or rehost management servers with corresponding tiers (eg. Cluster Master with indexers, Deployer with Search Head Cluster,etc.).
At this point, I’d like to highlight the most critical part of the migration, which is the Indexing Tier and, in relation, the Existing Data Migration.
Indexing Tier Migration
The indexing tier is the most crucial and lies in the centre of the Splunk Enterprise environment since these servers are the ones that do the main task of indexing. Before diving into the methodologies for migrating indexing servers, let’s briefly cover the data structure of indexes within these servers to shed some more light on this area.
Indexer Server Data Structure
Splunk uses a tiered storage architecture within its indexers to efficiently manage and store data for indexes. This architecture allows Splunk to optimise storage costs and performance by dividing data into different storage types based on its age and access frequency. The primary storage types within Splunk indexers for indexes are:
Hot/Warm/Cold Storage:
Hot Bucket: This is the first storage tier where newly ingested data lives. It contains the most recent data and is actively being written to and read from. Hot buckets are typically stored on fast and expensive storage devices like SSDs to ensure quick access and indexing performance.
Warm Bucket: As data ages in the hot bucket, it "rolls" into the warm bucket. Warm buckets are still actively searchable but are typically moved to slower and more cost-effective storage, like traditional HDDs. This transition is part of Splunk's data "bucket" rotation process.
Cold Bucket: Data eventually rolls from warm to cold buckets as it becomes less frequently accessed. Cold buckets are optimised for long-term storage on even more cost-effective storage, such as archival storage or cloud-based solutions. While data in cold buckets is still searchable, it may take longer to retrieve due to the slower storage medium.
Frozen Storage:
Frozen Bucket: After a certain retention period, data may be frozen, meaning it’s no longer searchable but is kept for compliance or historical purposes. Frozen buckets can be stored in offline or less accessible storage, like tape backups or long-term cloud storage solutions.
Thawed Data:
Thawed Bucket: If data needs to be made searchable again, it can be "thawed" from frozen storage and brought back into the searchable index. This is typically done when historical data becomes relevant again, often for audit or compliance reasons.
The main burden of the migration of indexing servers into AWS is lying on the hot buckets where in a real-time environment, the indexer servers will always have hot buckets that are being written and read. Therefore, a simple rehost migration strategy is not possible to move the indexer servers into AWS without a downtime of indexer servers, since live data is being processed by the servers.
Therefore, order and method of migration for your Splunk Enterprise environment plays a crucial role in successful migration of the whole system without any major interruptions.
To make this migration possible, you need to first stop ingesting data from forwarders into the indexers and secondly you need to roll your hot buckets into warm buckets where you can move the indexed data without any corruption to the indexed data.
But if you require no downtime for the Splunk indexers then this migration needs to be handled in a different approach, since stopping ingesting data and rolling the hot buckets are not an option in case of a no downtime requirement. Therefore, you need to use the capabilities of Splunk Enterprise configuration to establish a replatform strategy rather than moving your indexing servers to AWS.
In this strategy, you need to establish a multi-site cluster structure configuration on AWS, and provision new indexer servers which are going to be operating under the same environment as a second site. You could distribute new servers across several availability zones within a region if you have requirements of DR capability.
Storage Solution for your new Indexing Tier
During this replatform strategy of your indexer servers, you could also switch your storage solution into a cloud native solution provided by Splunk: Splunk Smart Store. This is basically using any object storage in its backend (in this case AWS S3). It will give you better data storage options and it’s also cheaper compared to the requirement of keeping adequate capacity of EBS volumes for each indexer in standard configuration according to your Splunk’s search and replication factor.
Therefore, it’s highly recommended to consider using Splunk Smart Store as a storage solution in AWS, which will reduce your operating costs in the long run.
Establishing a multi-site Splunk cluster on AWS gives you the ability to test your environment before going into the production as well. You can create a data feed from one of your servers, and provision a single Splunk search head server to test the capabilities of your indexing servers on AWS.
No existing data is being migrated at this point, we’ll discuss data migration in a separate section for indexer servers.
At the time of replatforming indexer servers, you can also create the Splunk cluster master server on AWS for the future management of your AWS indexer servers. If you already have configuration settings for your main site server, you can replatform the server into AWS or if you’d like to rehost, the current cluster master is also possible.
Existing Data Migration
For existing data to be migrated, new ingestion to the old servers should be stopped and all hot buckets need to be rolled into at least warm buckets to be transferred into AWS S3. Therefore, data migration should be your last phase of your migration, after Forwarder and Search Head servers are moved.
Data migration should only start when there is no hot bucket that is still in use by the indexer/search head servers. Once they are rolled into the warm buckets, data migration can start.
Depending on the size of your existing data, the migration strategy can vary.
For example, if you have the option to use AWS Snow products, moving the Splunk data with this method could be a viable option to consider according to the size of your existing data.
However, if you cannot use AWS Snow products , you will rely on the internet bandwidth of your enterprise. If you are already using AWS Direct Connect, you may have better bandwidth between your on-premises server and AWS.
Depending on the size of your existing data, data migration could take days, weeks or maybe even months, therefore advance planning of the data migration phase should be well aligned within the project timeline since the project could utilise your whole bandwidth and may impact other migration projects.
For the migration of existing data, you could create an S3 bucket to move data from on-premises to AWS. For this purpose, you need to create an S3 bucket and provide proper access permissions to your AWS indexer servers for re-indexing your existing data into the Smart Store S3 bucket (if you use it as your storage solution).
For data migration you could use several options to establish a connection between your indexer server to AWS S3;
- You could set up “rclone” configuration to use the rclone tool to upload your data to AWS S3. Based on experience , this tool option gave the most flexibility of options for limiting bandwidth, multipart upload and speed.
- You could use “aws s3 cp” if you are allowed to install awscli on an on-premises server.
- You could set up a S3 storage gateway to provide a mount point to the on-premises server.
- You could use the recent release of AWS which provides you a mountpoint for AWS S3. (Read more here)
For the reindexing data, you could either use the Splunk AWS Add-on tool to select S3 as data source, or if you’d like to follow a traditional method, you need to download the data to indexer servers itself for re-indexing. However, this method will require additional EBS volumes to be attached to indexer servers according to the data size that you are trying to migrate and there will be a download cost from S3 back to EBS volumes within AWS.
Therefore, it’s highly recommended to use Splunk Add-on for AWS to connect your S3 bucket that contains your data.
After the migration of your existing data into the Splunk Smart Store, you won’t need the S3 bucket that you created to migrate your existing data.
After the data migration, you can now switch your on-premises search head client facing DNS name to be directed to the AWS load balancer CNAME, and you’ll now have a fully functional Splunk Enterprise environment running on the AWS.
In summary, migration of a successful Splunk Enterprise environment to AWS requires expertise on migration, good project planning and an intense collaboration with the appropriate stakeholders. And of course, Nordcloud can help your journey to move your Splunk Enterprise environment to AWS - feel free to reach out to us using the form below.




Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
