
Improve your sustainability on cloud using intermittent data pipelines
If cloud applications and data products are designed correctly, they can help organisations to reduce the carbon emissions and energy consumption of their servers.
Organisations want to improve their sustainability. Servers obviously generate carbon emissions. But cloud efficiencies and smart data design can help organisations reduce these carbon emissions by up to 84%. This can mean a staggering 65% reduction in energy consumption.
Designing data pipelines to be intermittent means better flexibility, cost control, efficiency and, most importantly, sustainability.
So, first of all, what is intermittency?
Renewables are intermittent by nature. This is because wind, solar and hydro start and stop generating energy intermittently. And because people want to continuously (not intermittently) power our homes, cities and countries, in order to use renewables, we’ve had to address this intermittency challenge.
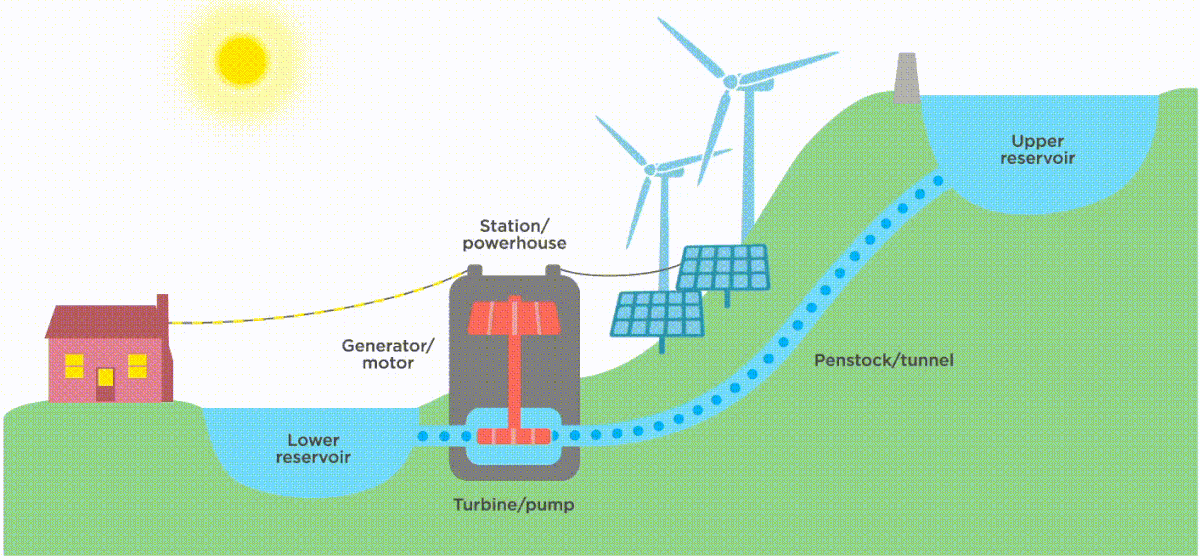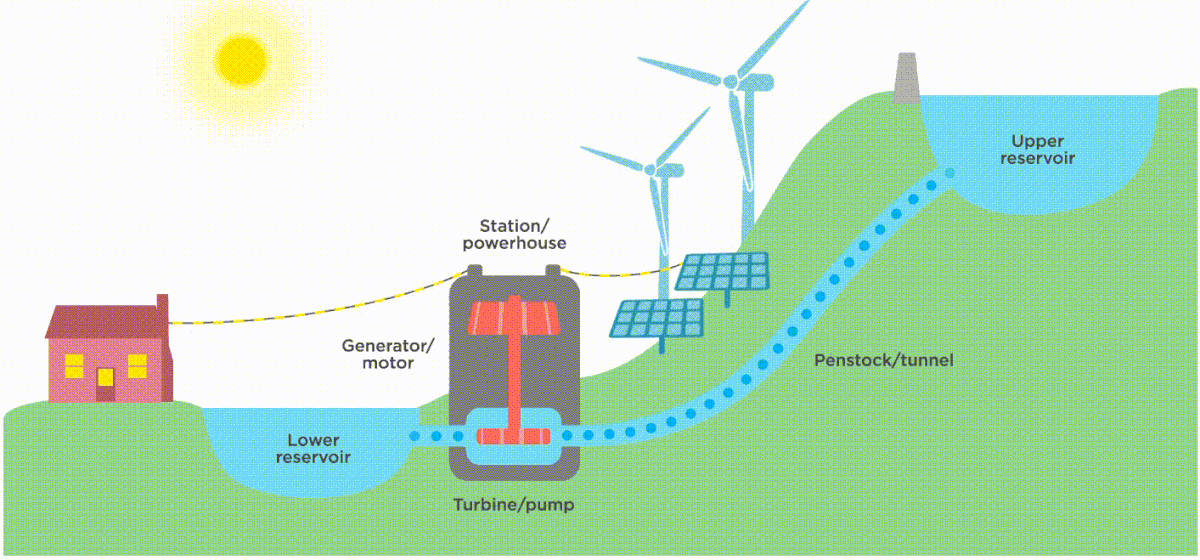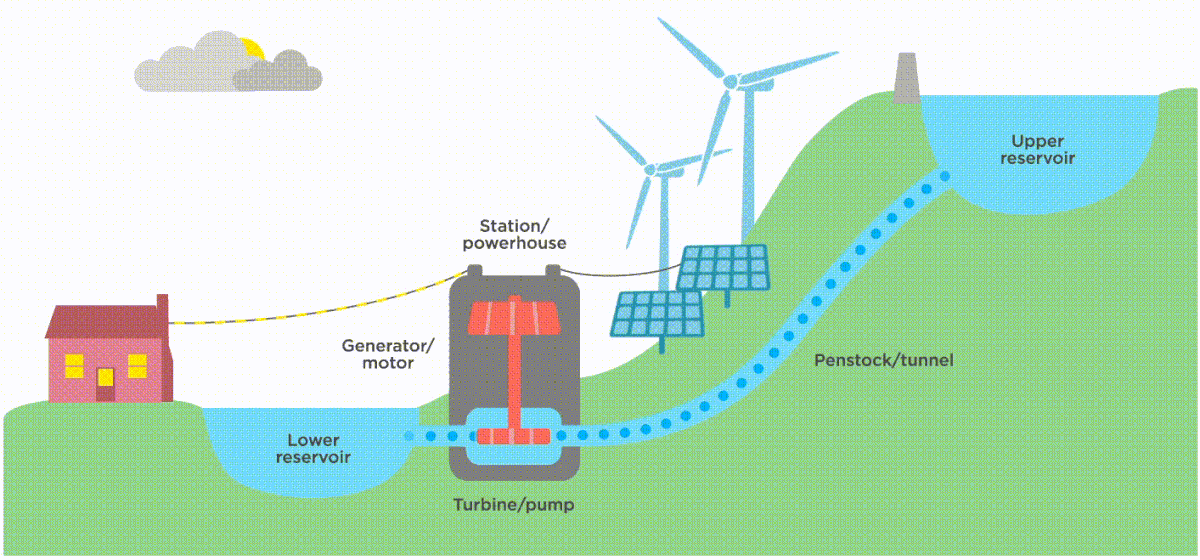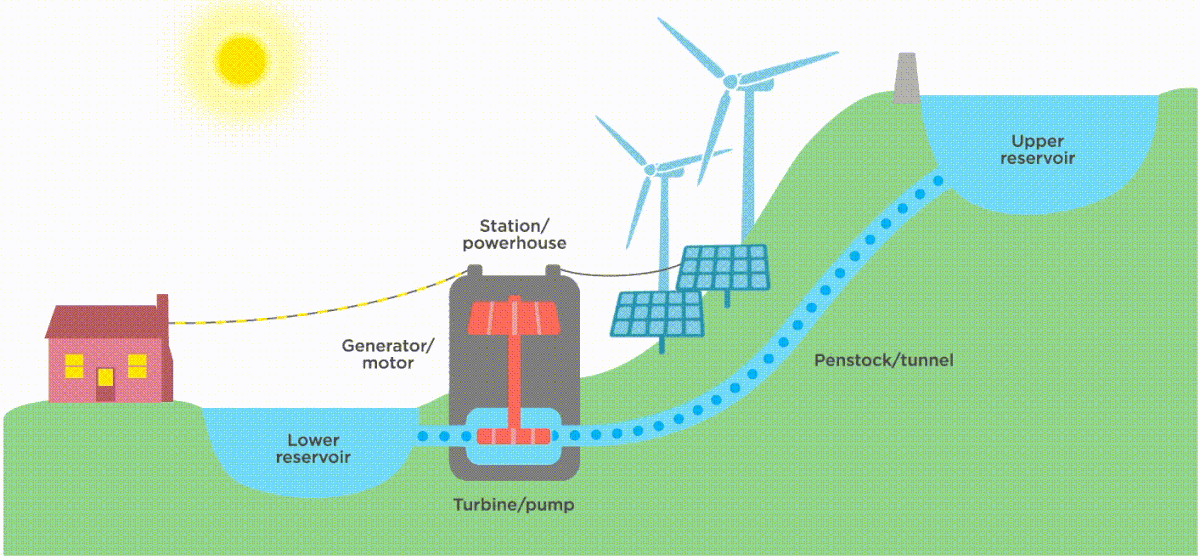
Image source: https://www.ucsusa.org/resources/how-energy-storage-works
So, how do we use renewable energies even though they’re intermittent?
Well, we “store” renewable energy by leveraging periods of strong wind/ solar/ tide (or downstream flow for hydro-turbines). In the case of hydroelectric turbines, we might leverage this overproduction of energy to fill up a water reservoir so that at times of peak demand when supply is insufficient, we can empty the reservoir to enable a steady production of electricity.
The cool thing? We can apply this intermittency principle to data design - and it helps you run on the cloud in a more sustainable way.
Sustainability on cloud: Why it matters
Sustainability is about trying to mitigate the environmental footprint of a service or product and leveraging all possible angles to reduce it.
In the context of cloud computing, people often ask, ‘Is public cloud more sustainable than on-premise data centres?’
Moving to cloud lets you leverage hyperscaler efficiencies that mean you rely on more renewable energies, for example. However, sobriety in cloud usage is just as (or even more) important, and helps to extend the life cycle of devices being used.
To begin, I’ll briefly touch on these three reasons public cloud helps organisations improve their sustainability:
- Hyperscaler efficiencies
- Cloud elasticity
- Cloud’s potential for serverless computing
1. Hyperscaler efficiencies
For on-premise data centres, the energy mix used to generate power usually depends on the country in which they’re located. On the other hand, the three main public cloud hyperscalers (Google Cloud, Microsoft Azure and AWS) have ambitious targets related to reducing the emissions/ footprints of their data centres and operations.
For example, cloud hyperscalers have targets to:
- Invest in renewable energy projects
- Limit water consumption and optimise the cooling process
- Transition to a circular economy model



2. Cloud elasticity
On-premise servers need to be oversized for both storage space and computing power. This ensures continuous operations of their workloads but also requires the duplication of data and running these servers 24/7.
This is not the case with public cloud.
Because of cloud’s elasticity, and having storage and compute fully decoupled, an organisation only has to pay for what it uses. There is no need to oversize, as hyperscalers maintain servers with server lifecycle extension in mind (as per hyperscaler commitments).
3. Cloud’s potential for serverless computing
Cloud native services or applications can leverage the serverless concept, which basically means turning on servers to process and work on data, and then turning the machines off once the process is finished.
Why we design data pipelines to be intermittent
Sustainability on cloud goes beyond cloud adoption. Cloud efficiencies and smart data design is crucial.
Data pipelines should be designed to be intermittent to allow for improved efficiency, flexibility, cost control and sustainability.
Event-driven architectures and serverless architectures, for example, rely on native, serverless services, meaning they can be turned on when needed and turned off once the processing or workload is finished.
Plus, there is no need to overdimension the cluster of servers that will be spun up to process data with the elastic capabilities of the cloud. For example, during the data processing workload, if any workload needs more computing power, more machines can be turned on. If it needs less computing power, then some machines will be turned off, to ensure that it only uses exactly what the workload/ pipeline needs: no more, no less.
This is why at Nordcloud, we design our pipelines to be intermittent, so that we:
- Only use machines when needed
- Avoid having idle machines running 24/7 that we have to power (and customers have to pay for)
Data design best practices for sustainability
What does it mean in practice to use data design to improve your sustainability on cloud? The challenges are the same as with renewable energy and it comes down to differences in timings from:
A. Demand
B. Supply and production
A. Demand
Best practice 1: Be realistic about your data demand
- Prioritise high quality, exploitable data over large, unreliable datasets
- Be smart about the kind of data “freshness” you need
- If you consult a dashboard once every few hours or every day, you probably don’t need it to be updated using the fastest possible data pipeline running 24/7
- It makes more sense to process a batch of data every hour, for example. That way you spin up the machines and shut them down once they’ve completed the job, instead of streaming that processing 24/7, and both paying for and consuming that energy continuously
- Design pipelines to fit your use-case, rather than oversizing and overprovisioning
- Basically, you don’t need to buy a Formula 1 car to get to the office every day. Although there are specific use-cases for which streaming is needed, for the rest, we should aim at efficiency and cost control with serverless or event-driven approaches.
Best practice 2: Form a sound, future-proof data strategy
Data is a growing resource, and the value lies in re-using and sharing data while it’s being enriched. That’s why it’s so key to establish a data strategy with a common framework that:
- Relies on prepared data that can be re-used by all stakeholders, instead of re-processing the same raw data over and over for slightly different needs across the company
- You therefore avoid duplicating data, which is something that only makes storage more expensive. Data duplication also makes it hard to understand where data is coming from and how it was processed, ultimately leading to governance issues (who has access, who owns the data and what is the data lineage)
- Focuses on collecting only data that is relevant today and will most likely be relevant in the future, and making sure it’s coherent with current and future needs
- Is collaborative, because data and data products are meant to be shared across the organisation. Every business unit will have different needs and will rely on different subsets of raw data to be processed into final usable data products
B. Supply and production
Best practice 3: Design pipelines to autoscale
The “elasticity” of the cloud means that we can rely on pipelines to autoscale, when we design them well. This means:
- Architecting the solution to avoid paying for “idle” costs and rely on the “serverless” mindset which is also more environmentally friendly. Therefore, machines don’t run 24/7 for the sole purpose of processing data when possible
- Establishing a “Common Data Model” to create a more collaborative culture in organisations, and a smarter and more sustainable path
- This may look like designing and modeling tables so that any produced data asset can be interoperable and compatible with each other, so that these assets can be reused across the organisation
- In the sustainability practice world, it goes even further by making data products interoperable and compatible across industries (Datasets coming from industries like Water, Energy, Waste Management…)
Best practice 4: Optimise storage tiers
Two main storage tiers in the cloud are:
- The default (and most expensive) standard tier, which ensures data is available instantly at any time
- Archive tiers, which allow data to be stored with longer retrieval times. This storage consumes less energy (and is significantly cheaper)
Optimising and leveraging storage tiers to become more efficient can look like using:
- 3 to 4 different storage tiers to fit the immediate retrieval needs for hot data and different archiving needs for colder data
- Archive tiers for data that is not consulted or queried very often, potentially once per month, quarter or year
- Automations for data lifecycle management, for example, when a partition of a dataset has not been modified for 3 months, then this partition can be switched to another storage tier
Best practices: In summary
In short, it’s about ensuring that downtime generates no cost, aside from storage, and that there’s no irrelevant data duplication. It means best practices are followed when designing and modeling data, so querying is efficient and fast (partitioning and clustering mean only the relevant subsets of data are scanned with the most frequent queries).
It also means energy consumption is fully optimised and that cloud native services used come from regions (or data centres) powered by renewables.
Hyperscaler services to consider
There is a suite of hyperscaler native services to tackle sustainability monitoring and mitigation in:
- Google Cloud
- Microsoft Azure
- AWS
1. Google Cloud
- Carbon Footprint: Measure, report, and reduce your cloud carbon emissions for both Google Cloud and Google Workspace (Meet, Gmail, Docs, Sheets, Slides, ...).
- Active Assist: Explore recommendations and insights to manage cost wisely, mitigate security risks proactively, maximise performance, reduce the carbon footprint of workloads (monitoring and identifying unattended projects or VMs to remove them among other things).
- Google Cloud Region Picker to help select the region with the highest percentage of Carbon Free Energy (CFE), but also taking into account latency and cost (using Compute Engine pricing).
- Environmental APIs (Solar API to scale solar adoption and installation, and understanding environmental changes to take personal action with Pollen, and Air Quality APIs).
- The Google Earth Engine connector to Google BigQuery to allow for easier integration and enables customers to get geospatial insights to help them analyse and mitigate climate risks.
2. Microsoft Azure:
- Microsoft Cloud for Sustainability Solutions to start recording, reporting, and reducing environmental impact of organisations with
- Project ESG Lake (preview) to allow organisations to build a single source of truth for environmental, social, and governance (ESG) data.
- Emission Impact Dashboards to calculate and monitor carbon emissions from the customer environment:
3. AWS:
- AWS Customer Carbon Footprint Tool to track, measure, review, and forecast the carbon emissions generated from your AWS usage.
- AWS Data Exchange makes it easy to find, subscribe to, and use third-party sustainability-related data in the cloud.
Final thoughts
The challenge of improving sustainability in cloud presents opportunities to fully leverage smart data design.
The value of data should increase the more it’s used, enriched and shared across an organisation. Designing data pipelines to be intermittent can help you achieve better flexibility, cost control, efficiency and, most importantly, sustainability.







Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
