
Scalable setup of Azure Databricks Workspace for multiple teams
21 February 2024
Many organisations choose Databricks as a core technology for their data platform. The goal of such a platform is to offer a foundation that abstracts concerns such as ops, security, cost efficiency etc from the product teams and allows them to focus on building data products.
In this post we describe one of the possible solutions for evolving data platforms in large organisations that want to have a scalable setup that supports many teams while having means to ensure compliance and common standards within the platform.
Initial setup: shared resources within a single workspace
The initial setup usually tries to deliver the core functionality - allowing product teams to develop and deploy data products. At its simplest the starting point looks as the following:
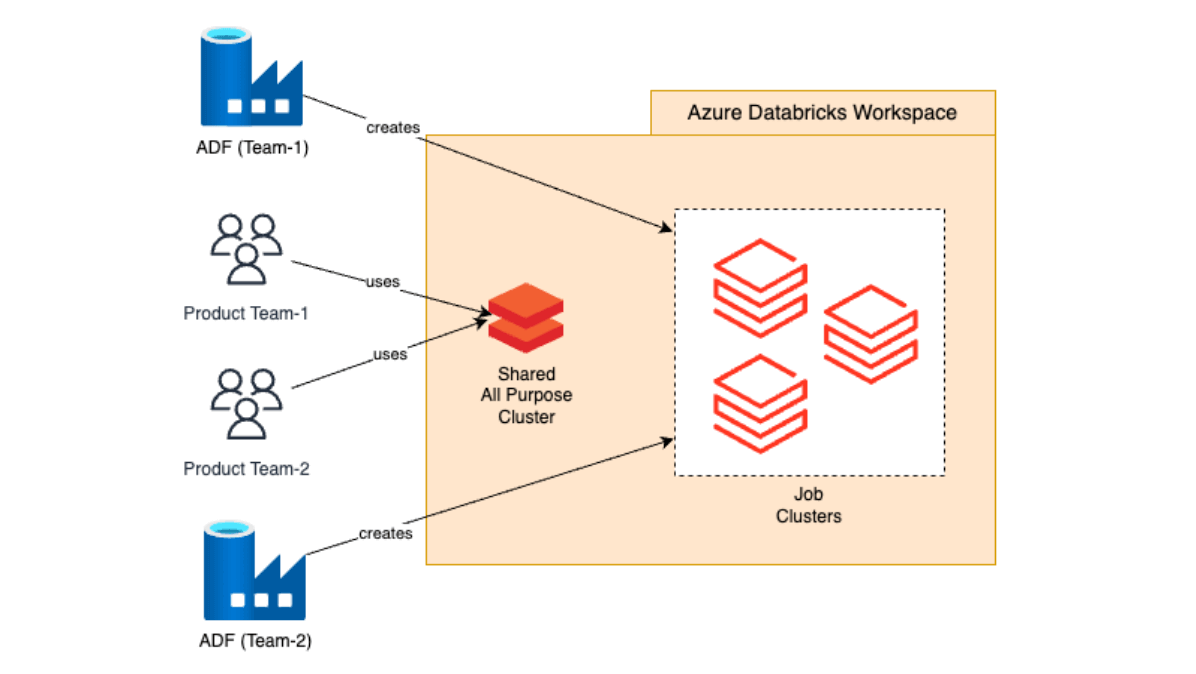
Key points:
- Multiple development teams have access to one or more shared All Purpose clusters. All Purpose clusters are interactive and are used for development only.
- When a data pipeline is ready, it can be then scheduled via an orchestrator to be run on a time schedule or upon a condition. The orchestrator (e.g. Azure Data Factory) spawns a Databricks Job cluster to run an actual workload. Job clusters are ephemeral and non-interactive but cheaper compared to All Purpose clusters, making them a perfect match for automated, production workloads.
- To ensure users have minimal privileges required, product teams get "Can Attach To" to the All Purpose cluster.
- The Platform team is a workspace admin and has full privileges to all resources within the workspace.
Disadvantages
Although this configuration provides teams with a simple development and production setup, it quickly proves to be not scalable and has many drawbacks.
Too restrictive permissions for product teams
Minimal Databricks cluster access level - "Can Attach To" is insufficient for many development tasks. E.g. adding libraries to the cluster or changing auto termination timeout.
Dependency collisions
Different teams may require using versions of libraries that can be incompatible with each other inside one cluster.
Noisy neighbours
A sudden spark of activity in the All Purpose cluster, or increased number of scheduled jobs can affect other teams. For instance, by reaching a limit in shared Databricks instance pool size.
Large overhead for platform team
Lack of adequate permissions for users creates a load of service request to the platform team to change or troubleshoot the configuration.
No cost separation
In the given model it is not possible to systemically enforce attributing resources costs to the team that spawned those resources.
Solution 1: dedicated workspace per product team
One of the possible solutions to the presented problem can be the complete replication of Databricks infrastructure per team. That is, every product team gets its own dedicated Databricks workspace. All resources - All Purpose cluster(s) and Job clusters are created within that workspace.
Without going into much detail, this solution, although addressing most of the challenges, in certain circumstances might not be feasible for the following reasons.
Lack of control
The Product team will receive admin rights in the workspace and hence compliance, if required, cannot be enforced.
Network constraints
In VNet injection mode every workspace requires a VNet address space with /16 - /24 CIDR blocks. This can be not feasible for large organizations with complex network topologies.
Solution 2: single workspace with a dedicated instance pool per team
Another solution is to stay within a single workspace but to introduce a dedicated instance pool per team. Compute policies are then used to restrict usage to only the dedicated pool.
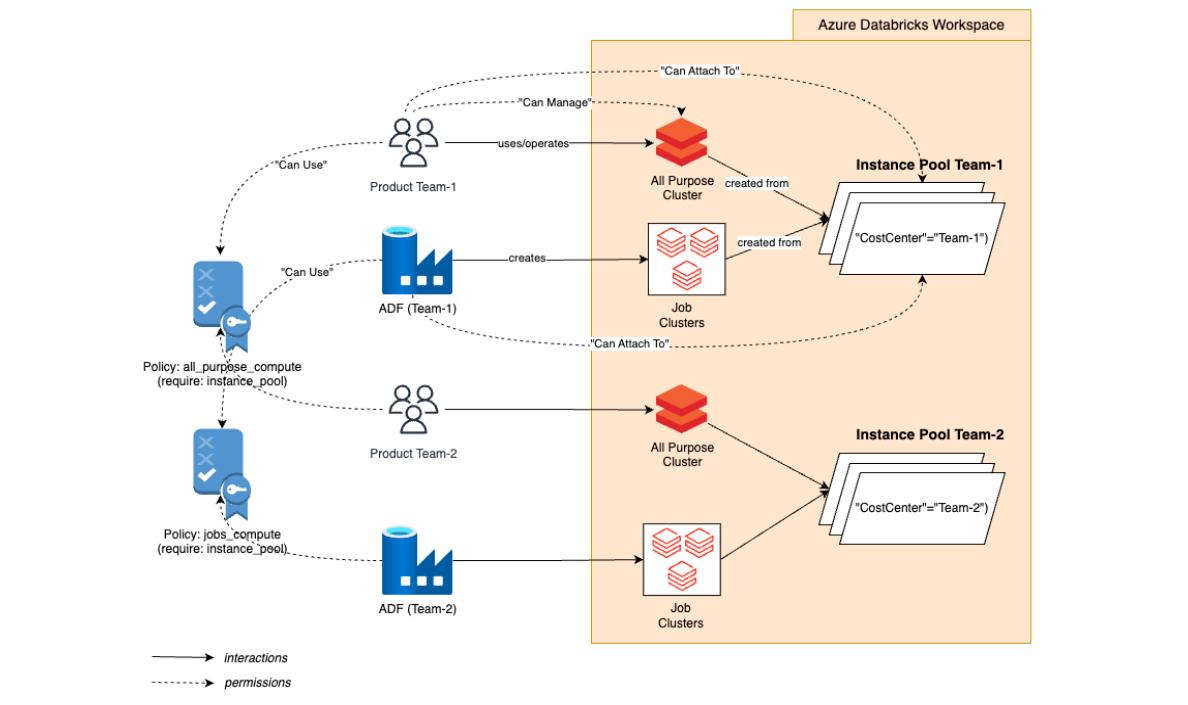
This combination can ensure that:
- team members (user principals and the team’s ADF managed identity) will not have access to resources, except for the ones, created from a dedicated instance pool
- team members can have control over their All Purpose cluster (e.g. add libraries)
- proper cost attributing is enforced (i.e. by enforcing tagging on team’s resources)
Below is a table of permissions for one of the teams on the workspace resources:
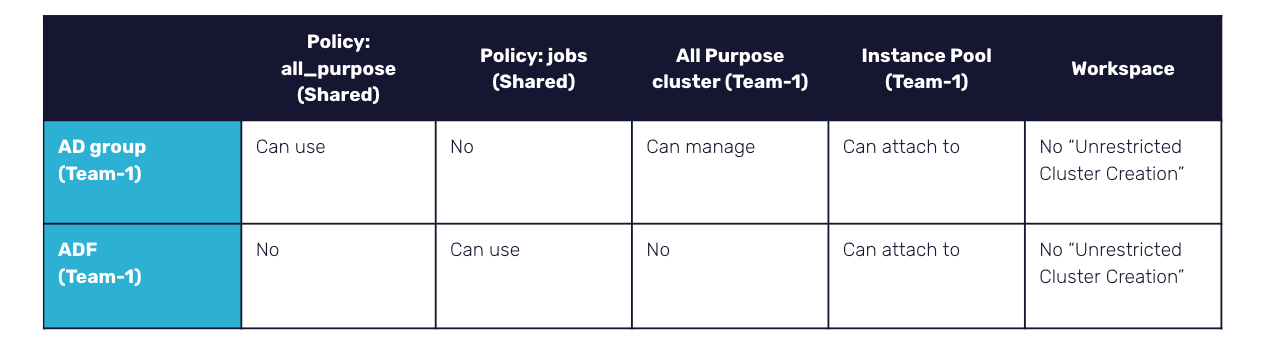
Another product team will respectively get access to all their dedicated resources (All Purpose cluster) and the same “Can Use” to shared policies.
Cost separation
Cost separation in the suggested model relies on tags and based on the way tags are propagated in Databricks [link].
In short, workspace tags take preceding over tags on instance pool level, instance pool tags get propagated onto the underlying resources (i.e. VMs and DBUs).
Let’s say an organisation adopts a standardised way to do cost tracking and chargeback - a tag “CostCenter”. Then the following needs to happen:
- Omit the Databricks workspace itself from tagging (at least with the tag CostCenter)
- Tag every new instance pool for a new team with the respective CostCenter
Because the suggested permission model doesn’t allow any team to create/use resources unless those are materialised from their pre-tagged instance pool, all costs will be correctly attributed, as long as the platform team correctly pre-creates and configures instance pools.
Conclusion
Unlike core Azure resources, Databricks currently does not offer a flexible fine-grained permission model that would allow it to build a truly scalable and secure setup for large organisations.
Using existing access levels and different resource types, specifically Databricks Instance Pools and Databricks Policies it is possible to find a balance and achieve a data platform architecture where:
- teams have control where they need it - e.g. on their development environment
- teams don’t depend on other teams
- the CICD process can be standardised and followed universally
- the platform team is relieved from many repetitive service duties
- costs separation is supported out of the box
This setup can be interesting for large organisations that are building a unified data platform and looking for a setup that offers good flexibility, yet leaning towards centralization on a spectrum ‘Fully Centralised” – “Fully Federated”.




Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
