
Embrace Kubernetes and Decrease Infrastructure Spend
Energyworx is a Dutch scale-up that produces big data platforms for customers in the energy sector. Their customers, both energy suppliers and network operators, use the platform to process and store time series data from all the energy meters placed in houses and businesses across their area of operations. The platform is used to automate business processes like billing and predicting energy usage. During our project, we assisted them in migrating their data processing pipelines to Kubernetes, achieving over 50% savings on costs for their compute workloads.
The Challenge
Before Nordcloud was introduced to this project, Energyworx had already built a large, distributed platform on GCP, mostly using managed services such as App Engine, Dataflow, Pub/Sub, Bigtable and Big Query. The problem they were experiencing was that as the load on their platform rose, so did the costs. The biggest cost factor in the project was Google Dataflow. Therefore, at the start of our project, the decision to migrate a significant compute load from their platform to Kubernetes was made.
Energyworx chose to write their platform using Python for two main reasons:
- It’s a language their data scientists were familiar with, and since Python is an interpreted language, it made it possible to implement an important feature in their platform
- Customers can insert their own data transformations (“rules”) into the processing pipeline, written in their own Python code.
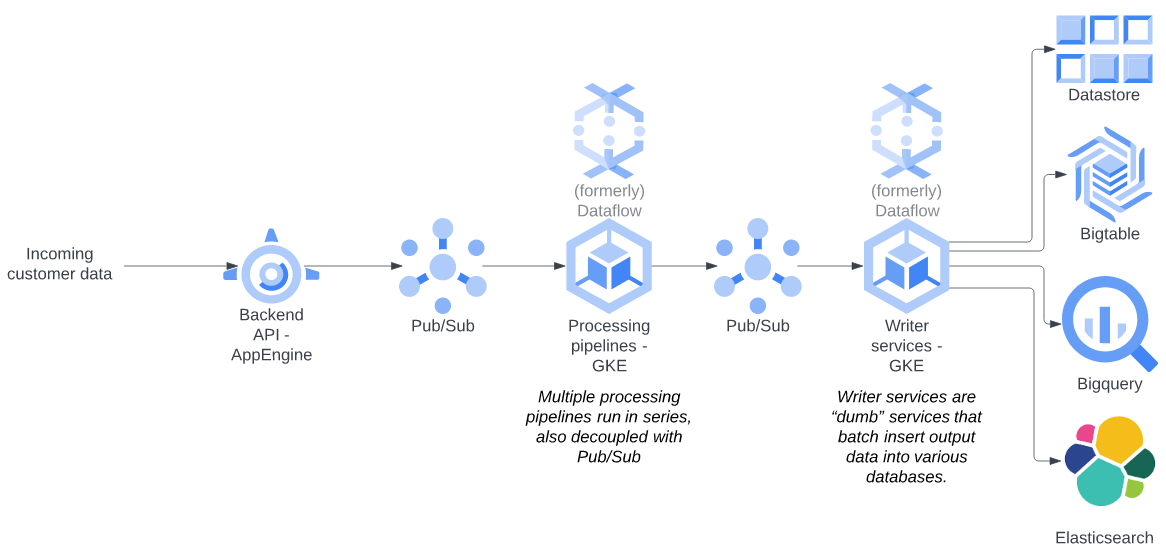
Using Google Dataflow
Google Dataflow is a service that runs code developed specifically in the Apache Beam framework, which was developed by Google and is now open source . This framework was designed specifically to make it easier to build distributed applications that process substantial amounts of batched and streaming data.
With the Beam framework, engineers can create a processing pipeline in one of the supported languages (Python, Java, Go), and run their code on a Runner that supports the Beam framework, such as Dataflow, Apache Beam or Apache Spark.
Apart from the Beam framework itself, Dataflow also offered many other benefits:
- Dataflow pipelines are easy to deploy and integrate with other Google services, making it easy to get a product to market quickly.
- Dataflow is auto-scaling and abstracts away many of the problems of managing a distributed processing pipeline - It takes care of deciding which parts of your workload should run on which worker - Dataflow orchestrates this without much input being required. It also handles or simplifies problems like data deduplication, error handling and retrying failed external calls. In other words, it allows you to focus more on the inherent complexity of the problem domain, rather than the incidental complexity of a distributed system.
- Dataflow offers dashboards that give great insight into the current state of running services without developers having to put any effort into building them.
So, why migrate away from Dataflow?
Well, there were several reasons, but the most important reason was cost. Like with many managed services, you pay for all the functionality that they deliver by paying a premium on the compute resources. Compared to what you pay for regular Virtual Machines, a Dataflow instance, for example, costs 2.5x as much for the same CPU/RAM resources according to Google’s cost calculator at the time of writing.
That could be worth it, if you get enough value out of it, either by getting better performance than you’d get if you build your processing pipeline some other way, or by reducing operational headaches. For Energyworx, this was not the case, for several reasons:
- Performance of Python Dataflows
In Energyworx’ experience, the Python version of Dataflow in general performs worse than the Java implementation and lags behind in features. They also experienced frequent crashes where pipelines ended up in a state where they simply did nothing, causing tickets sent in by angry customers waiting for their data. Energyworx ended up having to dedicate significant amounts of time to monitoring their flows. Dealing with these crashes also caused data loss, application messages that were still in progress were lost when restarting.
- Limitations of the programming model
The way they had built their processing pipelines ended up growing ever further away from what you might consider a “canonical” Beam pipeline. Every time they ran into an edge case that the Python version of the framework did not (yet) support, they worked around this limitation by writing code outside of the Beam programming model. This code was a drain on the performance gains Dataflow could provide. On the other hand, since at the point we started the migration project, a large part of the codebase was not too tightly coupled to the Bbeam programming model. Therefore, it was simple to remove the Beam framework entirely and dockerize the pipelines, making it possible to run them on Kubernetes without a Beam runner.
- (Too) aggressive autoscaling
In Energyworx’ experience, Dataflow auto scales aggressively when a burst of data enters the system but does not scale down quickly enough after the data has been processed, causing a lot of unnecessary costs when large batches of data enter the system. While the auto scaling feature in principle was a big plus, not being able to tweak the autoscaling in a fine-grained way was a significant downside. In Kubernetes, we have complete control over the autoscaling behavior using Horizontal Pod Autoscalers.
- Dependency management
Apache Beam and Dataflow posed a challenge from the perspective of managing the code libraries used in Energyworx’ product. As you can see on this documentation page, the Dataflow runners come with quite a few python libraries already installed:
This posed challenges for evolving the product - since so many dependencies we wanted to use were bound to the version of Apache Beam we were using; we were effectively required to update all the dependencies at the same time.
This is especially problematic when we wanted to upgrade the version of the framework, and that updated version of the framework came with an upgrade for a dependent library that had breaking changes. This made the update extra complicated and introduced a new workload for the developers.
Upgrading the version of one of the dependent libraries was often not possible without upgrading the framework version and all the dependent libraries. That is of course a normal phenomenon when working with a large framework, but this became a much smaller problem after the Beam was no longer in the codebase.
So, I guess what I’m trying to say is that using a framework imposes a cost on your freedom to choose your other libraries, which shouldn’t really surprise anyone.
- Run anywhere
Finally, Energyworx is eventually hoping to deploy their platform on other cloud platforms as well (AWS/Azure) and running the workloads in Kubernetes brings that ambition one step closer to reality.
- Cost Saving
The autoscaling optimisations and change of tools can lead to a more mindful usage of resources and therefore, reduce the total spend of the platform.
Comparison summary table
| Previous Implementation (Dataflow) | New Implementation (Kubernetes) |
|---|---|
| Custom implementations require code to be placed outside the canonical Beam framework code, leading to loss of performance | There is no custom framework needed to guarantee high performance |
| Too aggressive autoscaling | Efficient k8s pod scaling process |
| Python libraries are all bound to Apache Beam updates, therefore if an upgrade is needed for one of the libraries, all the others also needed to be updated | Independent version deployment per python library selection |
| The solution is specifically designed to run in GCP | Flexible and cloud agnostic; can be run in any hyperscaler with little modification |
Problems encountered in the migration process
So, what kind of trouble did we run into when rewriting the processing pipeline to run as plain python docker containers? Well, mostly the problems inherent in distributed systems:
Data duplication
Data processing in the Energyworx platform occurs in several stages, decoupled from each other using Google Pub/Sub topics and subscriptions. One problem we simply had to deal with during the migration was taking care of data duplications. As described eloquently in this blog, one of the inherent problems of distributed systems is that you cannot have exactly-once delivery. Dataflow has built-in features for deduplicating the data in the platform. Without dataflow, we had to produce our own implementation.
We ended up going with several:
- Whenever possible, it is good to have idempotent writes. For example, writing the same data to Google Bigtable twice is not a problem. In this case, no further action was required.
- While we cannot have exactly-once-delivery, we could get (close to) exactly-once-processing: We ended up using a Redis instance to make sure that if a particular message was delivered multiple times, it was only processed once.
- Finally, it also occurred that data was duplicated for other reasons than multiple deliveries of messages, which resulted in data being inserted into Google Big Query multiple times. In this case, we could use materialiszed views in order to only show the latest entry for every object.
Autoscaling services within application
As mentioned earlier, data passes through several processing steps in the Energyworx platform which are decoupled with Pub/Sub topics. One reason for migrating to Kubernetes was the more granular control over the deployment autoscaling. This turned out to be both a blessing and a curse: While we now had tools that allowed us to tweak the scaling and throughput of the platform, we also had to use many of them. Some concerns to think about:
- Which metric do you use to auto scale a given workload? There are multiple options. CPU/Ram usage? Number of messages or bytes in a message queue? Waiting time for messages in a queue? For best performance across multiple environments in which the data going through the platform looked differently, we ended up using a combination of metrics: number of messages waiting in a queue and age of the oldest message in the queue.
- We had to pay special attention to the scale-down behavior of our deployments. Data entering the platform did not enter the system evenly; rather, there could be bursts of data at given times during the day. Though, however much data enters the system, we want to guarantee processing in a given maximum amount of time. So, a situation you want to avoid is where you have a message queue with a given number of messages waiting for processing, and as messages get processed, the deployment size scales down, with throughput decreasing along with it. In that case, you will end up with a “tail” of messages that end up taking way longer to process than they should. You can also encounter situations where the metric used to scale the deployment goes up and down, resulting in containers being de-scheduled and re-scheduled all the time, which severely hurts performance (“flapping”). In our case, using a sufficiently large stabilisation window solved both problems.
Failure handling
Finally, we had to take a bit more ownership for handling failure situations, whereas before they were covered by Dataflow. Two of them are:
- Dataflow handles retries when making external API calls
- Dataflow handles application state quite well (unless the whole pipeline crashes).
When refactoring the data pipelines, we had to come to grips with the fact that we had to do far more failure handling on our own. It turned out that when running thousands of containers in Kubernetes, containers get killed all the time. Either having containers get killed halfway through processing, or halfway through sending out output data, caused both losses in performance and data duplication. So, we had to design the new services with that in mind, making the service responsible for gracefully handling such situations.
We added termination handlers to every service, so that the services could finish their current batch of work when receiving a SIGTERM. We also determined that I/O of the processing pipelines should be as close to transactional as possible. In practice, this means that when processing, it is best to save any output/database writes for that unit of work until the end of processing. In this way we could make the acknowledging of input messages and sending out of output messages behave as much like a transaction as possible.
Results
Based on the work we did in this migration project, Energyworx achieved several business outcomes that ensure their platform can keep evolving in a sustainable way in the coming years:
- The platform achieves the same business value for customers with over 50% savings on compute workloads.
- By moving workloads away from Google managed services to Kubernetes, Energyworx is now one step closer towards being able to deploy the platform on other Hyperscaler platforms.
- New avenues have been opened for cost savings - Now that the team is more comfortable using Kubernetes, we want to migrate more components from other managed services (such as Google App Engine) to Kubernetes. Also, we’d like to try out pre-emptive GKE nodes to see if they can provide us with stable-enough compute while saving money.




Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
