
Managing application incidents efficiently with alert instructions as code
Authors: Henri Nieminen & Perttu Savolainen
In this post we describe application incident management, and how we handle it at Nordcloud. We propose improvements to our current process, and evaluate those by implementing changes to our open-sourced tooling we use for managing alert configurations. We will showcase how to define alerts and alert instructions as code.
Application Incident Management
Incident management is a core feature of application maintenance, if something is going wrong in your application you would like to know about it. Incidents might vary from issues that slightly affect user experience to larger disruptions that could cause data loss.
“Effective incident management is key to limiting the disruption caused by an incident and restoring normal business operations as quickly as possible.” (Google SRE, chapter 14)
The best way to minimize the impact of disruptions in applications is to have a properly defined incident management process. The process should make sure that the correct people will get notified with the information required for quick evaluation of the severity of the issue.
Incident management in Nordcloud Managed Cloud Applications
Managed Cloud Applications (MCA) offers application management for cloud native applications. MCA takes the ownership of applications running in production and makes sure that they are and continue to be satisfactory to use.
The incident management process in MCA has been automated using third party services, internal tooling, and by using open-source software. The core of the process is application monitoring which defines when an alert should be raised from an application and what the severity of the issue might be.
Alert Configuration
Alert configuration defines:
- what is being monitored,
- when an alert should be triggered, and
- what should happen when the given threshold is breached.
Cloud providers allow you to provision resources using templating languages, which can be used to define alert configurations. The templating languages allow you to understand what kind of alert configuration has been deployed, and how it would change if you update it. The infrastructure can also be easily duplicated or recreated from scratch.
For monitoring applications on AWS, we maintain two tools that we have open-sourced: AWS-cli which is used to generate alert configuration based on the existing AWS resources, and mca-monitoring that is used to deploy the alerts. Alert definitions are maintained in a yaml file, which is easy to read and maintain. You can see an example of an AWS Lambda error alert definition in the image below (Figure 1).

Figure 1: Example of alert configuration for AWS Lambda errors
Application incident management instructions
Incident management instructions are used to define possible initial steps to take when resolving a specific incident. Instructions should be easily readable and precise, so that anyone can quickly understand and execute the listed actions. The instructions are often located in the applications operative documentation, often referred as runbook, and maintained manually separate from the alert configuration. You can see an example of an alert description in a runbook below (Figure 2).
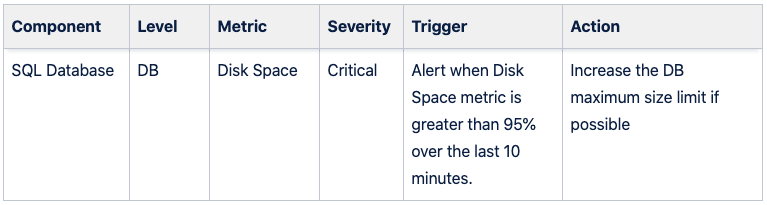
Figure 2: Example of alert description with instructions
The challenges in maintaining alert instructions
Maintaining alert instructions in a quickly accessible location makes handling incidents faster and easier. However, when they are maintained manually separate from the actual alert configuration, managing them requires extra work to keep them aligned because you have to update them in multiple places.
Whenever new alert definitions are added or old ones are updated, there is a risk that the instructions are not updated correctly to the runbook as it is an additional manual step. On top of this it is not always clear where to find the instructions, or their location could have changed, which may lead to unnecessary extra steps taken in order to find the correct up to date instructions.
In the worst case scenario you might spend time looking for the instructions for an incident only to realize that the instructions for that type of incident have not been defined. Another issue we have noticed is that alert instructions might have different styling between runbooks, meaning that you might need to spend extra time interpreting each format or styling.
Alert instructions as code
There are multiple immediate benefits when defining alert instructions in the alert configuration:
- Alerts should always be actionable: defining alert instructions forces you think about the actionability.
- There are no extra steps required to find the alert instructions.
- When the instructions are missing from the alert definition, it’s clear that they cannot be found elsewhere.
- The instructions and alert configurations are in a single configuration, and the changes are applied by automated deployments.
- The information is always up to date and matches the alert definition.
Having alert descriptions and instructions in a machine readable format allows one to process them to almost any desired format. Automating this process would be an integral part of the solution. As one would store the alert configuration in a version control system, the added benefit would be a complete history of the alert instructions. These obvious benefits are similar to what you get by defining and documenting your API in the source code and generating the representations from the source.
One downside with this approach is that whoever needs to manage the alert instructions, has to be familiar with the version control and document format. Inline editing in some of the version control platforms might help with editing the instructions, but still some users might be uncomfortable to edit a structured document they are not familiar with.
Proof of concept
What we want to achieve:
- To have a document format that allows the user to define alert instructions.
- mca-monitoring should be able to deploy those instructions to AWS.
- AWS CloudWatch alerts should notify the correct people with the alert instructions.
- Paging tool should display the instructions with the alert notification.
To get started we need to define a suitable place in the alert configuration for the instructions, which requires only minimal changes to mca-monitoring.
For the alert instructions in AWS CloudWatch, the alert description field works well. There is one restriction with this field as it has a length limitation of 1024 characters, which is plenty enough. Next we will show how to setup application monitoring on AWS using mca-cli and mca-monitoring, and how to include and test that the alert instructions also work.
Setup the monitoring
For generating initial alert configuration we will be using mca-cli which you can find on GitHub.
To get started clone the repository and run link command, which will make mca-cli available globally:
git clone git@github.com:nordcloud/mca-cli.git
npm linkTo generate a monitoring setup with mca-cli, you will need to point to an AWS profile (find instructions from AWS docs on how to configure profiles). Mca-cli will generate baseline alerts configuration for the resources existing on the AWS account for all the services listed in the command. To generate alert configurations for all the Lambdas on the account defined for the profile exampleprofile with stage dev, run the following command:
mca monitoring init --region eu-west-1 --profile exampleprofile --stage dev --output monitoring --service lambdaThis will create a monitoring directory that includes everything needed to define and deploy the monitoring resources. Mca-monitoring will be included as a dependency used to carry out the deployment.
Configure the alerts and alert instructions
Default alerts will be applied to all the resources defined in the configuration file, which can be extended or altered by defining resource specific alerts. Alerts are based on AWS CloudWatch metrics, each resource type has some default metrics but you can also create custom metrics.
In the following example you can see how to define default alert instructions for Lambda Error metrics, these need to be defined in config.yml:
custom:
default:
lambda:
Errors:
enabled: true
autoResolve: false
alarm:
critical:
threshold: 1
evaluationPeriods: 1
alarmDescription: |
- Evaluate the criticality of alert:
* Check the amount of errors
* If there are a lot of errors inform the product owner immediately
- Find the requestId of the error with CloudWatch Insights query:
fields @timestamp, @message
| sort @timestamp desc
| filter @message like /ERROR/
- Get the logs for the requestId:
fields @timestamp, @message
| sort @timestamp desc
| filter @requestId = "requestIdHere"
- Check if a development ticket exists of this issue
* If not create oneDeploy the monitoring
Run the following commands to install the dependencies, set up the resources for AWS CDK deployment, and deploy the monitoring:
npm install
npm run bootstrap
npm run deployTo verify that the alerts were properly deployed you can check them with AWS cli:
aws cloudwatch describe-alarms --profile exampleprofile --region eu-west-1After deploying you can see the description of the alert in CloudWatch Console. As you can see the line breaks don’t show correctly in there (Figure 3).

Figure 3: Alert description in AWS CloudWatch
Test the alert escalation
Testing alert escalation can be done by triggering them with AWS cli:
aws cloudwatch set-alarm-state --profile exampleprofile --alarm-name "example-alarm-name" --state-value ALARM --state-reason "Alert escalation test"
The command sets the alarm state manually to a selected value, which in this case triggers the Cloud Watch Alert. The triggered alert is connected to the paging system which displays the alert like this, with the defined instructions (Figure 4):
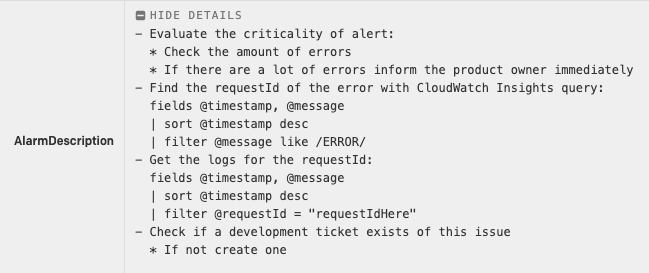
Figure 4: Alerts instructions in the paging system
Conclusion
We have shown our current process of managing alert instructions in the operational documentation of applications, and implemented an improvement in the form of a proof of concept. Initial observations indicate that the practice of handling alert instructions with the alert configuration would be a small change in the implementation but a huge improvement for the process of incident management. This concept would improve the following parts of our incident management process:
- accessibility of alert instructions would skyrocket,
- it would be easier to keep alert instructions up to date and matching with the alert configuration, and
- alert actionability would be perfected.

Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.
