
Data Lake best practices in AWS
Post • 3 min read
Many businesses are looking into enabling analytics on many different types of data sources and gain insights to guide them to better business decisions. A data lake is one way of doing that, where you have a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. Data analysts can in a data lake then leverage the data with their choice of analytics and machine learning services, like Amazon EMR for Apache Spark, Redshift, Athena, and more.
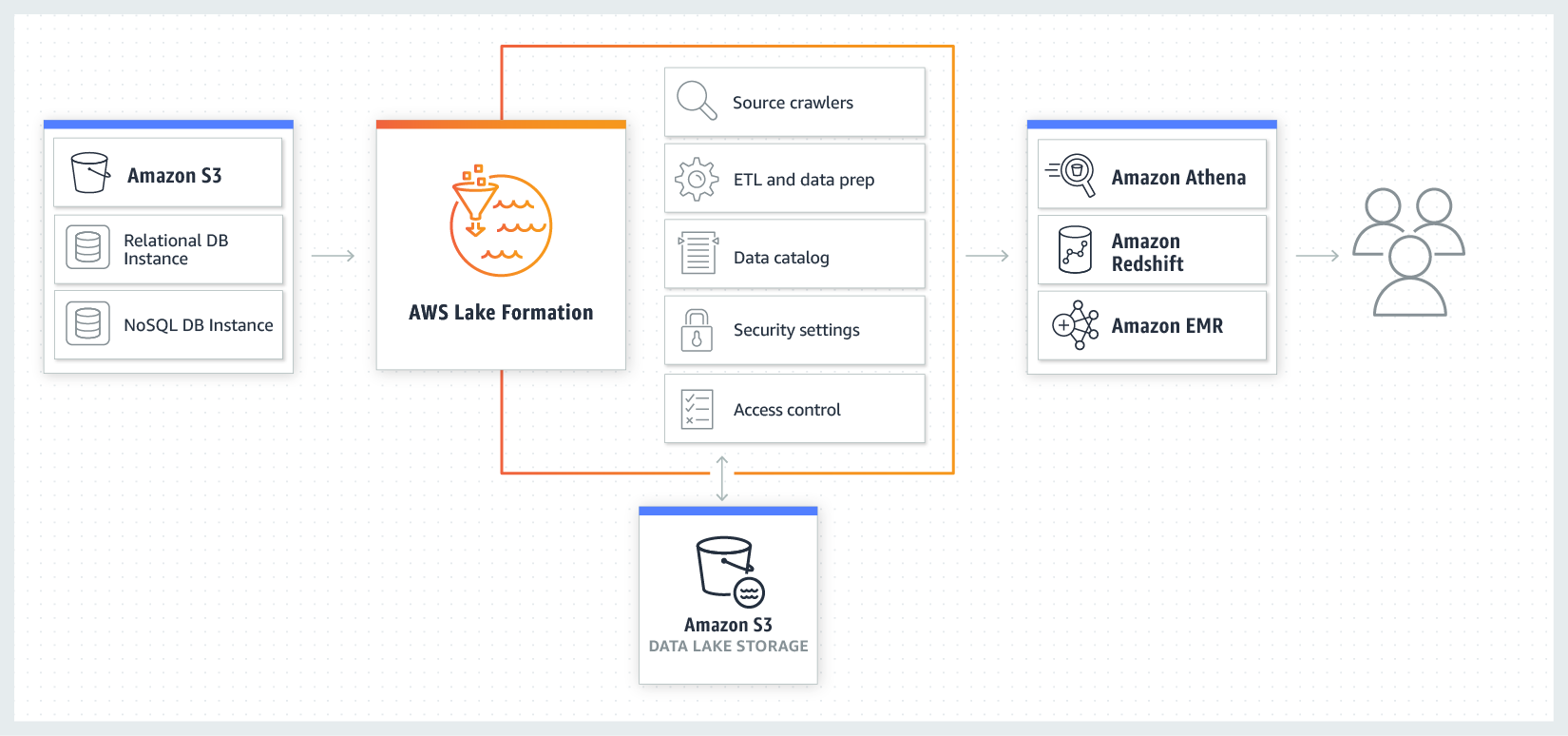
AWS Data Lake Formation
AWS Data Lake Formation is a new tool that makes it easier for businesses to setup a data lake - something that previously was a big undertaking taking months can now be broken down into just a few days of work. Data Lake Formation will automatically crawl, clean and prepare the data which you in turn can use to train machine learning models to dedupe based on what you want the data to look like. The most interesting functionality from the new Data Lake Formation might be the centralized dashboard for secure access on table and column level across all tools in the data lake - something that previously has been quite complicated and required third party tooling.
Data lake best practices
Best practices for utilizing a data lake optimized for performance, security and data processing were discussed during the AWS Data Lake Formation session at AWS re:Invent 2018. The session was split up into three main categories: Ingestion, Organisation and Preparation of data for the data lake. Your current bottleneck may lie in all or any of these three main categories, as they often interlink - so make sure to look into all of the categories to optimize your data.Ingestion
The main takeaway from the session was that S3 should be used as a single source of truth where data ingested is preserved. No transformation of data should happen in the ingestion S3 storage. If you transform the data, it should be copied to another S3 bucket. To optimize ingestion so that you don’t have a bucket full of old data at all times, you should also look into utilizing object life cycle policies so that data that you aren’t using gets moved to a cheaper storage class such as glacier. This especially makes sense for data that is outside of your time-scope and that is not interesting for analytics anymore. Getting data in from databases can be a pain, especially if you are trying to use replicas of on-premise databases. AWS recommends that instead of using database replicas, utilize AWS Database Migration Tool. This makes it easier to replicate the data without having to manage yet another database. If you use a AWS Glue ETL job to transform, merge and prepare the data ingested from the database, you can also optimize the resulting data for analytics and take daily snapshots to preserve the database view of the records.Organisation
Organisation of the data is usually a strategy that comes way too late in a data lake project. You should already in the beginning of the project look into organizing the data data into partitions in S3 and partition the data with keys to align with common query filters. It is for example sometimes better to create multiple S3 buckets and then partition the buckets on year/month/day/ instead of trying to fit all of your data into one S3 bucket with even more granular partitions. This does in reality depend on what your most common queries look like. Maybe you need to partition on months instead of years depending on your usage.Preparation
For mutable data use a database such as Redshift or Apache HBase but make sure to offload the data to S3 when the data becomes immutable. You can also append delta files to the partitions and compact them on a scheduled jobs to keep the most recent version of the data and delete the rest. Remember to compact the data from source before you do analytics - the optimal size is between 256 and 1000 MB. If you need fast ingestion than grabbing the data from S3 you can utilize streaming data to Kinesis streams, process the data with Apache Flink and push the processed data to S3. If you’d like some help in AWS Data Lake Formation, please feel free to contact us.
Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.

Ilja’s passion and tech knowledge help customers transform how they manage infrastructure and develop apps in cloud.
Ilja Summala
LinkedIn
Group CTO