
Private: Building operational resilience for FSI businesses
Post • 6 min read
A lot has been discussed and written about the recent TSB bank fiasco that saw its customers unable to access their banking services. The interesting thing is the planned downtime was supposed to last only 4 hours but instead went on for almost 48 hours (12 times more) for many of it’s customers, and left them ranting and raving about how helpless they felt while the bank took its (long), sweet time to sort out their mess!
There are few fundamental issues here, but the one I want to focus on is the fact that this isn’t the first time it happened with TSB (it also occurred in April 2018) or within Financial Services & Insurance (FSI) vertical – there already have been occasions when an IT systems meltdown happened unplanned, or a planned maintenance lasted 12 times longer than expected. At the same time in a world where we talk about Robotic Process Automation (RPA) & Artificial Intelligence (AI) taking over everything that’s mundane, repeatable and quick to learn, do we really understand the problem fully enough to find a solution to building an enterprise business that’s operationally resilient?Firstly, let’s understand why Operational Resilience (OpR) is important in FSI:
- Threatens the viability of firms within FSI and causes instability in financial systems.
- Introduces significant reputational & business risk within the ecosystem, hampering growth and confidence for all participants involved.
- Hinders the ability of firms to prevent and respond to operational disruption.
- How can you not get it right after you have failed many times?
- How long is long enough to be unexpected?
- How do we reward for failures?
How can you not get it right after you have failed many times?
“The true sign of intelligence is not knowledge but imagination” - Albert Einstein The point being, we need to apply new age design thinking into age old processes and do some right brain activities to come up with out-of-the-box ideas. You might think it’s easier said than done but going back to the principle of design thinking – empathising with the user- is a great place to start. Since FSI is such heavily regulated sector, it needs to develop focus areas based on an end-to-end lifecycle of business services (i.e. inception, delivery & maintenance) that impacts its market participants, profitability and risks directly. In the diagram below, I look at an example of a business service – “Retail Mortgages”. Looking specifically at this service, the FIs need to think how they can break it down (for OpR) into three key pillars – Focused Services, Technical Enhancement & Risk Management, followed by a framework that identifies, maps, assesses, tests & governs the whole mechanism in a periodic way. This is exactly where public clouds are such key enablers for this new world design thinking due to the flexibility, security, standardisation and resiliency they provide. As you introduce new business services into this framework the communication and governance should be standardised and in-line with your internal audit policies, only then will you be able to achieve true OpR by investing in all the aspects of that service. This also helps you answer questions like ‘should we buy more capacity and IT staff for testing a CRM system or should we improve the OpR of business-critical mortgage services?’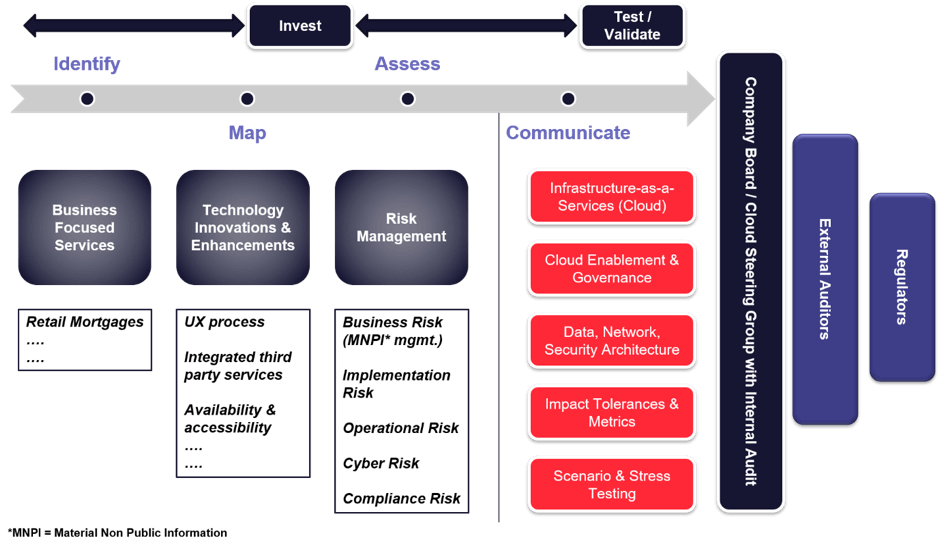
Business Architecture for OpR Framework in public clouds
How long is long enough to be unexpected?
When I ask this question to some of my colleagues in financial services, their response is typically synonymous to the answer you might get if you ask someone ‘how long is a piece of string?’ which frustrates me. Ultimately, you don’t know until you measure it. Once you have applied some design thinking on your business services the next step is to measure & communicate them. With public cloud there are numerous ways to develop an automated process or introduce new tooling that can help set-up impact tolerances specific to your business service. You can run stress testing and simulate numerous operational scenarios and report back on a management dashboard, (without significant capital expenditures) present it to your company board, internal audit teams (to match alignment) and keep it ready for your external auditors when they ask for it. You can therefore measure your OpR and predict the expected downtimes in a much more accurate way rather than running into long and unexpected downtimes.How can we reward failures?
This is a bit of a grey area hence it is important to get straight to the point – financial institutions put aside a lot of money for paying fines to regulators, compensating customers for loss of service and confidence, and at the same time, giving big pay-outs to staff for achieving irrelevant goals that are not in line with business focus areas. To fix this, the overall governance framework needs to set goals specific to selected business services, empower staff with set of right tools that helps run & manage the operations and have board level oversight to measure goals through open, fair and transparent metrics that not only looks at internal participants but include the interest of market participants like customers & regulators. By having this mind-shift and moving to the public cloud, financial institutions can lower compensation towards failures and invest where they really need to. In a nutshellto build an operationally resilient public cloud infrastructure:
- Focus on business services in the order of highest priority based on your organisational goals, you will notice that by doing so the investments are going to the right places, in the right detail, in a timely and systematic way and failures are only going to make you better, not miserable.
- Set-up operational metrics and impact tolerances that will be collected and reported to measure your operational resiliency. Use tooling and automation offered within the public cloud to improve governance & actionability within your organisation.
- Manage business risk through goal setting and empower your teams with the right tools and transparent processes.
FSI ready high grade offering from Nordcloud
Nordcloud offers a full stack cloud offerings, starting from enablement, governance, migration to business service operations. Within FSI we have designed specific frameworks that comply with regulatory standards and can be adopted out-of-the-box with bespoke configuration. Letting you focus on your core business while we take care of everything else. Contact us here to learn more about how to build an operationally resilient business.Cloud computing is on the rise in the financial services - are you ready?
Download our free white paper Compliance in the cloud: How to embrace the cloud with confidence, where we outline some of the many benefits that the cloud can offer, such as:
- Lowered costs
- Scalability and agility
- Better customer insights
- Tighter security

Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.

Ilja’s passion and tech knowledge help customers transform how they manage infrastructure and develop apps in cloud.
Ilja Summala
LinkedIn
Group CTO