Four UI Design Guidelines for Creating Machine Learning Applications
Post • 6 min read
Previously, I've introduced three underlying general capacities of machine learning that are exploited in applications. However, they are not enough for designers to actually start building applications. This is why this particular post introduces four general design guidelines that can help on the way.
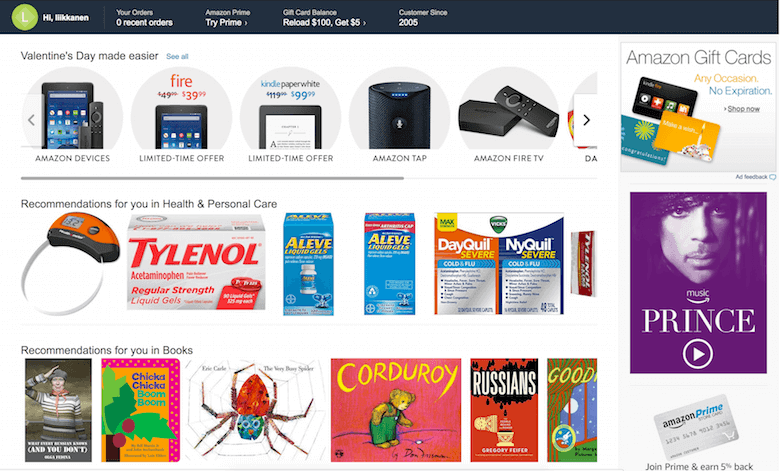 Amazon.com’s front page has been personalised for a long time. The selection offered to me looks somewhat relevant, if not attractive.
Currently, personalisation is foremost applied in order to curate content. For instance, Amazon carefully considers which products would appeal to potential buyers on its front page. But it will not end with that. Personalisation will likely lead to much bigger changes across UIs — for instance, even in the presentation of the types of interactive elements a user likes to use.
Amazon.com’s front page has been personalised for a long time. The selection offered to me looks somewhat relevant, if not attractive.
Currently, personalisation is foremost applied in order to curate content. For instance, Amazon carefully considers which products would appeal to potential buyers on its front page. But it will not end with that. Personalisation will likely lead to much bigger changes across UIs — for instance, even in the presentation of the types of interactive elements a user likes to use.
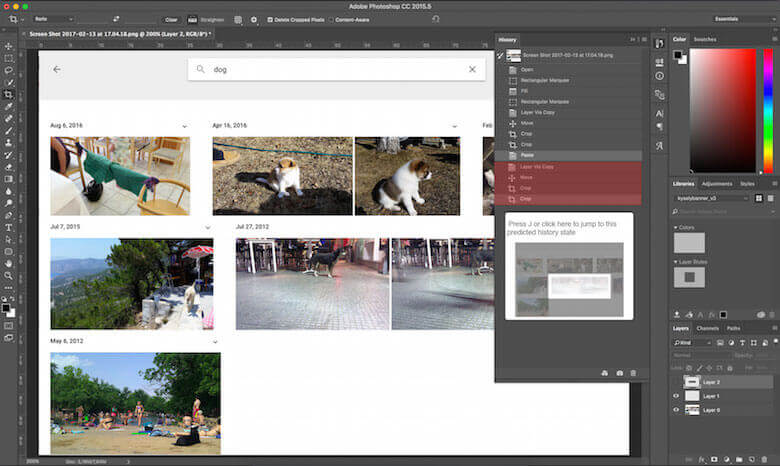 Mockup of a possible implementation of “predictive history” in Photoshop CC. The application suggests a possible future state for the user based on the user’s history and preceding actions and on the current image.
A funny illustration of a similar train of thought comes from Cristopher Hesse’s machine-learning-based image-to-image translation, which provides interesting content-specific filling of doodles. Similar to Photoshop’s content-aware fill, it creates most hilarious visualisations of building facades, cats, shoes, and bags based on minimal user input.
Mockup of a possible implementation of “predictive history” in Photoshop CC. The application suggests a possible future state for the user based on the user’s history and preceding actions and on the current image.
A funny illustration of a similar train of thought comes from Cristopher Hesse’s machine-learning-based image-to-image translation, which provides interesting content-specific filling of doodles. Similar to Photoshop’s content-aware fill, it creates most hilarious visualisations of building facades, cats, shoes, and bags based on minimal user input.
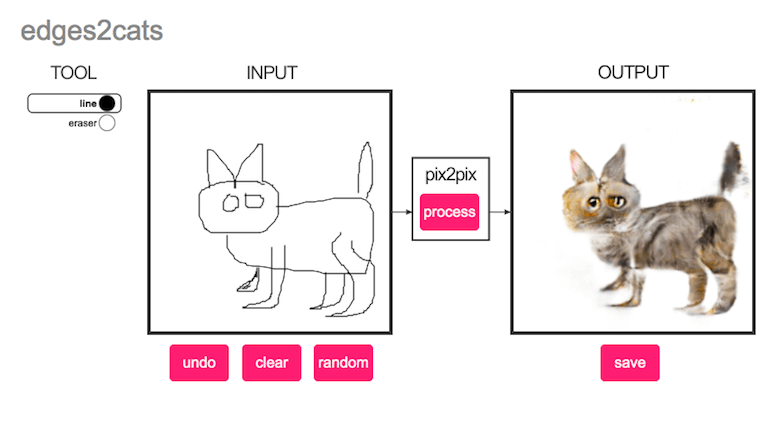 The edges2cats algorithm employs machine learning to finish your cat doodle as a photorealistic cat monster.
The edges2cats algorithm employs machine learning to finish your cat doodle as a photorealistic cat monster.
How can we and will we communicate machine intelligence to users, and what kinds of new interfaces will machine learning call for?
Machine learning under the hood entails both opportunities to do things in a new way, as well as requirements for new designs. To me, this means we will need a rise in importance of several design patterns or, rather, abstract design features, which will become important as services get smarter. They include:- suggested features,
- personalization,
- shortcuts vs. granular controls,
- graceful failure.
Suggested features
Text and speech prediction has opened up new opportunities for interaction with smart devices. Conversational interfaces are the most prominent example of this development, but definitely not the only one. As we try to hide the interface and underlying complexity from users, we are balancing between what we hide and what we reveal. Suggested features help users to discover what the invisible UI is capable of. Graphical user interfaces (GUIs) have made computing accessible for the better part of the human race that enjoys normal vision. GUIs provided a huge usability improvement in terms of feature discovery. Icon and menus were the first useful metaphors for direct manipulation of digital objects using a mouse and keyboard. With multi-touch screens, we have gained the new power of pinching, dragging and swiping to interact. Visual clues aren’t going anywhere, but they are not going to be enough when interaction modalities expand.How does a user find out what your service can do?
Haptic interaction in the first consumer generation of wearables and in the foremost conversational interfaces presents a new challenge for feature discovery. Non-visual cues must be used that facilitate the interaction, particularly at the very onset of the interactive relationship. Feature suggestions — the machine exposing its features and informing the user what it is capable of — are one solution to this riddle. In the case of a chatbot employed for car rentals, this could be, “Please ask me about available vehicles, upgrades, and your past reservations.” Specific application areas come with specific, detailed patterns. For instance, Patrick Hebron’s recent ebook from O’Reilly contains a great discussion of the solutions for conversational interfaces.Personalisation
Once a computer gets to know you and to predict your desires and preferences, it can start to serve you in new, more effective ways. This is personalization, the automated optimization of a service. Responsive website layouts are a crude way of doing this. The utilization of machine learning features with interfaces could lead to highly personalized user experiences. Akin to giving everyone a unique desktop and home-screen, services and apps will start to adapt to people’s preferences as well. This new degree of personalization presents opportunities as well as forces designers to flex their thoughts on how to create truly adaptive interfaces that are largely controlled by the logic of machine learning. If you succeed in this, you will reward users with a superior experience and will impart a feeling of being understood.
Amazon.com’s front page has been personalised for a long time. The selection offered to me looks somewhat relevant, if not attractive.
Currently, personalisation is foremost applied in order to curate content. For instance, Amazon carefully considers which products would appeal to potential buyers on its front page. But it will not end with that. Personalisation will likely lead to much bigger changes across UIs — for instance, even in the presentation of the types of interactive elements a user likes to use.
Shortcuts versus granularity
Photoshop is an excellent example of a tool with a steep learning curve and a great deal of granularity in controlling what can be done. Most of the time, you work on small operations, each of which has a very specific influence. The creative combination of many small things allows for interesting patterns to emerge on a larger scale. Holistic, black-box operations such as transformative filters and automatic corrections are not really the reason why professionals use Photoshop. What will happen when machines learn to predict what we are doing repeatedly? For instance, I frequently perform certain actions in Photoshop before uploading my photos to a blog. While I could manually automate this, creating yet another user-defined feature among thousands already in the product, Photoshop might learn to predict my intentions and offer a more prominent shortcut, or a highway, to fast-forward me to my intended destination. As Adobe currently puts effort into bringing AI into Creative Cloud, we’ll likely see something even more clever than this very soon. It is up to you to let the machine figure out the appropriate shortcuts in your application.
Mockup of a possible implementation of “predictive history” in Photoshop CC. The application suggests a possible future state for the user based on the user’s history and preceding actions and on the current image.
A funny illustration of a similar train of thought comes from Cristopher Hesse’s machine-learning-based image-to-image translation, which provides interesting content-specific filling of doodles. Similar to Photoshop’s content-aware fill, it creates most hilarious visualisations of building facades, cats, shoes, and bags based on minimal user input.
The edges2cats algorithm employs machine learning to finish your cat doodle as a photorealistic cat monster.
Graceful failure
I call the final pattern graceful failure. It means saying “sorry, I can’t do what you want because…” in an understandable way. This is by no means unique to machine learning applications. It is innately human, but something that computers have been notoriously bad at since the time that syntax errors were repeatedly echoed by Commodore computers in the 1980s. But with machine learning, it’s slightly different. Because machine learning takes a fuzzy-logic approach to computing, there are new ways that the computer could produce unexpected results — that is, things could go very bad, and that has to be designed for. Nobody seriously blames the car in question for the death that occurred in the Tesla autopilot accident in 2016. The other part is that building applications that rely on modern machine learning are still in its infancy. Classic software development has been around for so long that we’ve learned to deal with its insufficiencies better. As Peter Norvig, famous AI researcher and Google’s research director puts it like this:The nature of learning is such that computers learn from what is given to them. If the algorithm has to deal with something else, then the results will not be to your liking. For example, if you’ve trained a system to detect animal species from pet photos and then start using it to classify plants, there will be trouble. This is more or less why Microsoft’s Twitterbot Tay had to be silenced after it picked up the wrong examples from malicious users when exposed to real-world conditions. The uncertainty in detection and prediction should be taken into consideration. How this is done depends on the application. Consider Google Search. No one is offended or truly hurt but merely amused or frustrated, by bad search results. Of course, bad results will eventually be bad for business. However, if your bank started using a chatbot that suddenly could not figure out your checking account’s balance, you would be rightfully worried and should be offered a quick way to resolve your trouble. To deal with failure, interfaces would do well to help both parties adjust. Users can tolerate one or two “I didn’t get that, please say that again” prompts (but no more) if that’s what it takes to advance the dialogue. For services that include machine learning, extensive testing is best. Next comes informing users about the probability and consequences of failure, and instructions on what the user might do to avoid it. The good practices are still emerging. This text is from an article originally appearing in Smashing Magazine: https://www.smashingmagazine.com/2017/04/applications-machine-learning-designers/The problem here is the methodology for scaling this up to a whole industry is still in progress.… We don’t have the decades of experience that we have in developing and verifying regular software.
Get in Touch.
Let’s discuss how we can help with your cloud journey. Our experts are standing by to talk about your migration, modernisation, development and skills challenges.

Ilja’s passion and tech knowledge help customers transform how they manage infrastructure and develop apps in cloud.
Ilja Summala
LinkedIn
Group CTO